Chapter 3 - Strings¶
Introduction¶
In this chapter we will examine how to:
- Create and manipulate strings
- Search for a pattern within a string using regular expressions
- Extract information out of a string using regular expressions
Practice
You have 3 options to try out the examples in this tutorial
- Enter
python3on your Linux or MacOS terminal to launch the Python shell - Using this Google colab notebook
- Using this Python web interpreter.
Creating strings¶
- A string is a line of text between single, double or triple quotes (
' , ", ''', """). - Amongst these, the single-quotes is the most frequently used in Python.
- Triple quotes are used to crete multi-line strings
>>> 'This is a string'
>>> 'This is a string with "double-quotes"'
>>> "This is a string with 'single-quotes'"
>>> '''This is a
... multi
... line
... string'''
'This is a\nmulti\nline\nstring'Common string manipulation operations¶
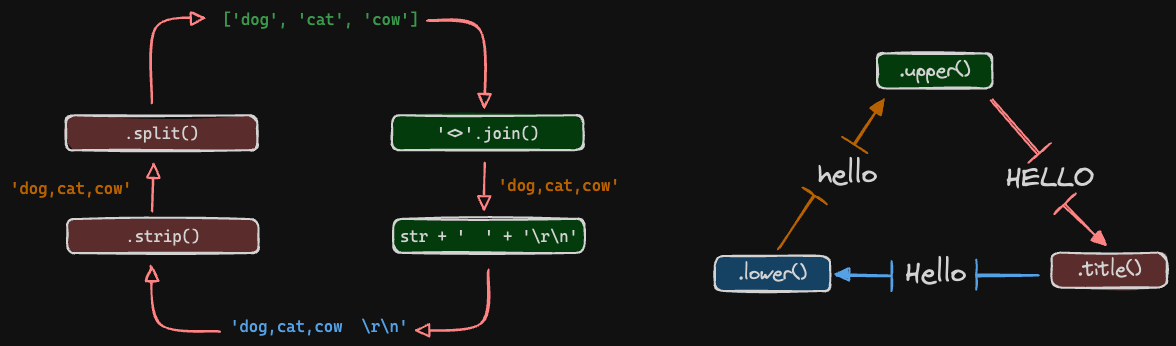
Here are three frequently used string operations:
- Find out the length of the string
- Slice a string and extract a portion of it
- Concatenate two or more strings
| Operation | Description |
|---|---|
len(s) |
Length of string |
s[0], s[1], s[-1] |
Index into the string. Just like with Lists, negative indices can be used to index from end of string. |
s[:3] |
Grab the part of string from start upto but not including index 3. In set theory this is represented as s[0:3), i.e., it is open ended. |
s[3:] |
Grab the part of string from index 3 to the end |
s[2:5] + k[3:5] + m[1:] |
Strings can be concatenated using the + operator.This example shows combining slicing and concatenation. A better approach to concatenate strings is shown next. |
Concat using .join()¶
While it seems intuitive to use the + operator to combine strings, the more efficient and Pythonic approach is to use .join().
It takes the format '<SEPARATOR>'.join(<LIST_OF_STRINGS>)
LIST_OF_STRINGS is the pieces of string you want to join - ['home', 'user', 'projects']
SEPARATOR is the character placed between the strings during the concat operation, i.e., <space>, /, +, etc
This approach, while being faster is also concise and clean. In the example, notice how the separator is specified in approach 1 (concat using +) versus 2 (concat using join).
# Approach 1
>>> 'apples' + ' ' + 'oranges' + ' ' + 'bananas'
'apples oranges bananas'
>>> 'apples' + ',' + 'oranges' + ',' + 'bananas'
'apples,oranges,bananas'
# Approach 2
>>> ' '.join(['apples', 'oranges', 'bananas'])
'apples oranges bananas'
>>> ','.join(['apples', 'oranges', 'bananas'])
'apples,oranges,bananas'
Strip¶
When a line of text is read from a file, it might have unwanted spaces and carriage-return characters (\r\n) around it.
.strip() removes these unwanted characters and cleans up the string.
>>> s = ' Simulation Passed \r\n'
>>> s.strip()
'Simulation Passed'Split¶
str.split('<delimiter>') is the opposite of '<delimiter>'.join([list]).
While join takes in a list and delimiter and turns it into a string, split takes a string and a delimiter and splits it into a list.
>>> s = 'apples,oranges,bananas'
>>> s.split(',')
['apples', 'oranges', 'bananas']Case sensitivity¶
Case conversion methods are quite handy. I use them more often than I realize.
I especially use them to perform case-insensitive comparison of strings: A.lower() == B.lower().
>>> 'hello'.upper()
'HELLO'
>>> 'HELLO'.title()
'Hello'
>>> 'Hello'.lower()
'hello'String matching¶
The .find() method is the easiest way to check if a substring is part of a string.
It returns a -1 if the substring is not found. If the substring is present, the starting index of the match is returned. I use it as a binary check to see if a string contains a substring.
>>> 'hello world'.find('cow')
-1
>>> 'hello world'.find('wor')
6
>>> if 'hello'.find('cow') >= 0:
... print('do_this')
... else:
... print('do_that')
...
do_thatRegular expressions¶
Compared to str.find(), regular expressions (RegEx) offers a more flexible method to look for patterns and extract parts of a string.
import re gives you access to this library. While it has a rich set of utilities with endless options and combinations, in this chapter we will look at some common use-cases.
The fundamental pattern is as follows. re.search() returns None if no match was found, and returns something if a match is indeed found.
import re
m = re.search(<SEARCH_PATTERN>, <STRING>)
if m:
print('Match found')
else:
print('No Match found')Simple pattern check¶
Consider the string s, this is how you can check if the pattern UVM_ERROR is present in it.
>>> s = 'UVM_ERROR: (/home/user/env.sv:14) [perf_test] Ingress rate = 100Mbps Egress Rate = 97Mbps'
>>> m = re.search('UVM_ERROR', s)
>>> m
<re.Match object; span=(0, 9), match='UVM_ERROR'>
>>> m = re.search('UVM_INFO', s)
>>> print(m)
NoneMultiple patterns¶
To check for multiple patterns in a string, simply separate the patterns with a logical OR | operator.
>>> m = re.search('ERR|Err|Fault|Error', s)
>>> m
<re.Match object; span=(4, 7), match='ERR'>Using patterns to extract¶
Apart from specifying exact strings, RegEx allows you to specify arbitrary patterns. In the example below \d+, in plain english, means check for one or more digits.
>>> m = re.search('Ingress rate = \d+Mbps', s)
>>> m
<re.Match object; span=(46, 68), match='Ingress rate = 100Mbps'>Instead of simply looking for a pattern, you can extract the part of the string that matches it. To accomplish this,
- Surround the portion of the
SEARCH_PATTERNyou want to extract with brackets() - If a match was found,
m.groups()holds the extracted portions
>>> m = re.search('Ingress rate = (\d+)Mbps', s)
>>> m.groups()
('100',)
>>> m.groups()[0]
'100'Special sequences and repetition¶
Similar to \d, there are few more useful special sequences.
| Sequence | Description |
|---|---|
\d |
Matches digits [0-9] |
\D |
Matches anything NOT a digit [^0-9] |
\w |
Matches any alphanumeric character, this include underscore [0-9a-zA-Z_] |
\W |
Matches any non alphanumeric character [^0-9a-zA-Z_] |
\s |
Matches white space |
\S |
Matches anything NOT a white space |
. |
Match anything |
^ |
Start match from start of string |
$ |
Match to end of string |
and a sequence when combined with a repetition operator makes specifying patterns even more powerful.
| Repetition | Description |
|---|---|
* |
0 or more matches |
+ |
1 or more matches |
? |
0 or 1 matches |
\d+= Match 1 or more digits\s+= Match 1 or more empty spaces.*= Match 0 or more of any character
A complex example¶
Consider the following example. We can specify a pattern to extract the file name, test, ingress rate and egress rate, from the string.
>>> s = 'UVM_ERROR: (/home/user/env.sv:14) [perf_test] Ingress rate = 100Mbps Egress Rate = 97Mbps'
>>> pattern = 'UVM_ERROR: (.*) \[(\S+)\] Ingress rate = (\d+)Mbps Egress Rate = (\d+)Mbps'
>>> m = re.search(pattern, s)
>>> m.groups()
('(/home/user/env.sv:14)', 'perf_test', '100', '97')
>>> # Unpack the groups into individual variables
>>> file, test, ing, egr = m.groups()(\d+)is used to extract the numbers(\S+)is used to extract the test name. Since[]are special characters, we have to escape them. This is why you see\[(\S+)\]. This will match for actual brackets[]and extract non-space characters using(\S+).- Finally, we extract the file name with
(.*), an arbitrary match of all characters betweenUVM_ERROR:and the start of the square brackets[.
Practice, Practice, Practice¶
That's it for this chapter.
The key to learning Python is practice. Set 15 minutes on a timer, fire up python3 on your Linux or MacOS terminal (or use this Python web interpreter) and practice some of the code in this chapter.
Read this next¶
Sign up to be notified when the next chapter is published!
Chapter 2: Numbers Table of contents Chapter 4: Coming soon
If you found this content useful then please consider supporting this site! 🫶
